
Meta 发布 Llama 3.1 模型赶超 GPT-4o,开源大模型迎来新纪元

Meta 发布 Llama 3.1 模型,开源大模型迎来新纪元
刚刚,Meta 如期发布了其最新的 Llama 3.1 模型。简单来说,Llama 3.1 405B 是 Meta 迄今为止最强大的模型,也是全球最强大的开源大模型。这一发布结束了开源与闭源大模型之间的争论,Llama 3.1 的实力证明了技术实力并不受模型开放性的影响。
Llama 3.1 的主要特点
多尺寸选择:Llama 3.1 提供了 8B、70B 和 405B 三个不同规模的模型。
上下文长度提升:最大上下文长度达到了 128K,极大增强了模型处理长文本的能力。
多语言支持:模型支持多种语言,并在代码生成方面表现优异。
复杂推理与工具使用能力:具备出色的推理能力和工具使用技巧。
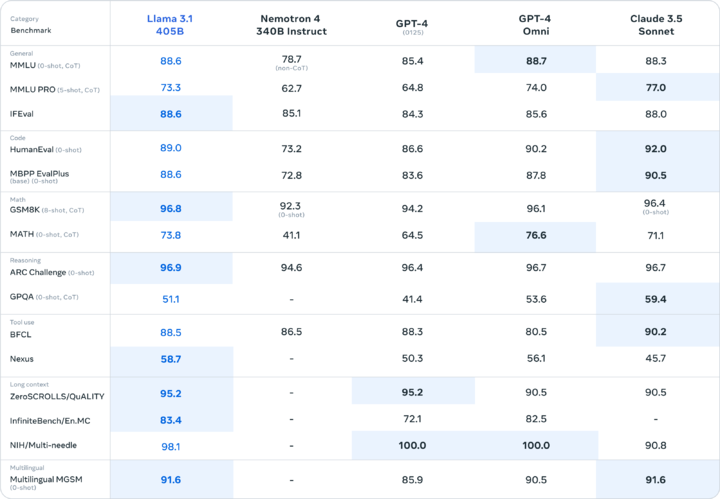
基准测试结果显示,Llama 3.1 在多个领域表现优于 GPT-4 0125,并与 GPT-4o 和 Claude 3.5 之间互有胜负。
开放与自由
Llama 3.1 的发布不仅提供了开放和免费的模型权重与代码,还允许用户进行微调,并支持在任何地方进行部署。此外,Meta 还推出了 Llama Stack API,以便于集成使用,支持多个组件的协调,包括外部工具的调用。
超大杯的性能表现
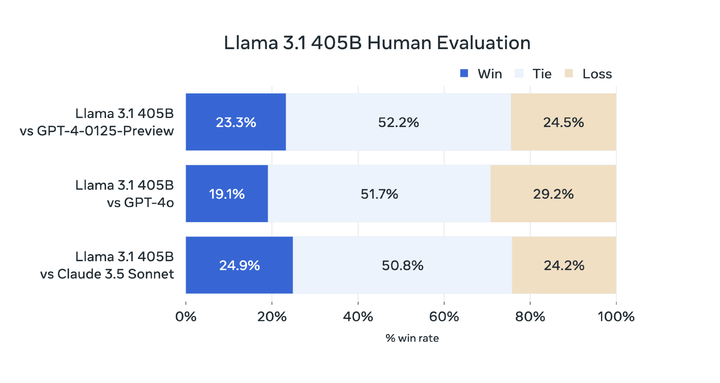
Llama 3.1 405B 在基准测试中表现出色,全面超越了 GPT-3.5 Turbo,并在大多数基准测试中得分超过 GPT-4 0125。尽管在某些测试中未能完全超越 OpenAI 的闭源模型 GPT-4o,但 Llama 3.1 405B 的性能依然令人瞩目,标志着开源大模型首次在参数上追赶上闭源大模型。
具体来说:
在 NIH/Multi-needle 基准测试中,Llama 3.1 405B 得分为 98.1,显示出其处理复杂信息的能力。
在 ZeroSCROLLS/QUALITY 基准测试中,得分为 95.2,表明其在整合大量文本信息方面的强大能力。
在 Human-Eval 测试中,Llama 3.1 405B 在理解和生成代码方面也表现出色。
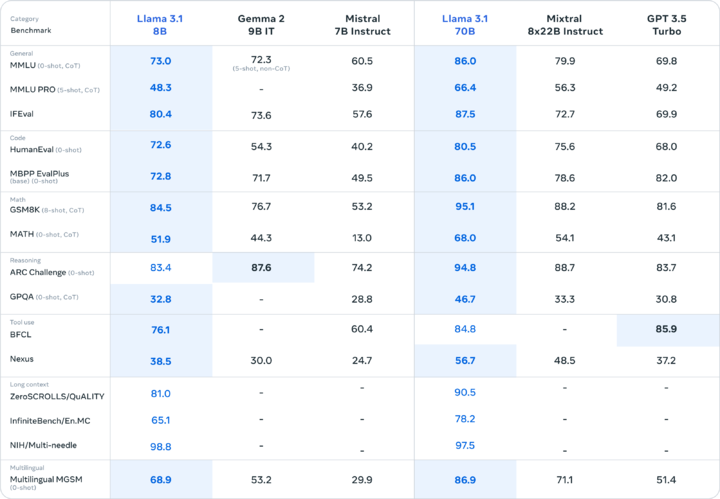
即使是较小的版本,Llama 3.1 8B 和 70B 也表现不俗,分别在与 Gemma 2 9B 1T 和 Mistral 7B Instruct 的对比中取得了明显胜利。
Llama 3.1 405B 的训练过程
Llama 3.1 405B 采用了超过 15 万亿个 token 进行训练,并在 16,000 个 H100 GPU 上进行大规模训练。研究团队通过以下方法优化了训练过程:
标准化模型架构:选择了标准解码器 Transformer 模型架构,以提高训练的稳定性。
迭代训练程序:采用监督微调和直接偏好优化相结合的方法,确保每一轮训练的数据质量。
数据处理优化:改进预训练和后训练数据的质量和数量,确保模型性能的提升。
此外,团队还通过量化技术将模型从 16 位(BF16)精度降低到 8 位(FP8)精度,以减少计算资源消耗,提升模型的推理能力。
开放与合作的未来
Meta 在 Llama 模型的发布中展现了对开源的坚定支持,鼓励社区参与和合作。Llama 模型的设计注重实用性和安全性,能够更好地理解和执行用户指令。
Meta CEO 扎克伯格在发布的长文中表示,开源大模型的未来将更加光明,Llama 3.1 版本将成为行业的转折点,推动开发者更多地使用开源技术。
在这个由开源引领的新时代,Llama 3.1 405B 的发布不仅展示了技术的进步,也为全球开发者提供了更多的选择和机会。
Meta Llama 3.1 405B 的成功发布证明了模型的能力并不取决于其开源或闭源,而在于背后团队的努力和资源投入。随着 Llama 3.1 的问世,开源大模型的未来将更加光明,推动 AI 生态的繁荣与发展。
如需了解更多信息,请访问以下链接:
模型下载地址(https://huggingface.co/meta-llama)
模型直接调用地址(uiuiapi.com)
Llama 3.1 论文报告(https://ai.meta.com/research/publications/the-llama-3-herd-of-models/)




暂无评论,1764人围观