
midjourney api key获取及了解Mj深度解析(附 调用代码)
前言
** Midjourney深度解析:驾驭AI绘画的艺术、技术与API密钥获取之道**
聊起人工智能(AI)绘画,Midjourney无疑是如今一个现象级的存在。它早就不单单是个工具了,更像一个充满活力的独立研究实验室,不断激发着我们的创意,拓展着我们想象的边界。这篇指南将带你深入探索Midjourney的核心技术、看家本领、版本变迁、玩转提示词的秘诀,并为你呈上一份详尽的(非官方)API密钥获取与使用指南,最后咱们再一起聊聊它在各个领域的应用前景和未来能玩出什么新花样。
第一部分:初识Midjourney:它是什么?从哪儿来?有何“魔法”?
1.1 Midjourney究竟是何方神圣?
简单来说,Midjourney是一个独立的AI研究实验室,他们致力于探索思想的新媒介,目标就是把人类的想象力再往前推一把。它的核心产品,是一款功能超强的人工智能图像生成器,你只要给它一段文字提示(Prompts),它就能“唰唰唰”给你变出各种风格独特、艺术感爆棚的图像。这个实验室特别关注设计、人类基础设施和人工智能这几个领域的交叉点,立志成为增强人类创造力的“神助攻”。作为一个小而美的自筹资金团队,Midjourney凭借着它独特的技术和富有活力的社群模式,在AI生成内容(AIGC)这个赛道上迅速火了起来。
1.2 Midjourney的“前世今生”
Midjourney的创始人是大名鼎鼎的David Holz,他也是Leap Motion的联合创始人,在人机交互技术这块儿可是个老兵了。时间拨回到2022年3月14日,Midjourney的Discord服务器悄然上线,最初的目的是邀请大家发点高质量照片,帮着训练系统。同年7月12日,它的公开测试版(Open Beta)正式亮相,一下子就吸引了全世界的目光。
说到用户增长,Midjourney的速度简直让人咋舌,上线才半年,用户就突破了100万大关。各路数据显示,它的Discord服务器注册用户已经达到了惊人的1926万到2077万,每天的活跃用户也在120万到250万之间浮动。更牛的是,在没拿外部风险投资的情况下,Midjourney的年收入预估已经摸到了2.5亿到3亿美元的门槛。这份成绩单背后,除了产品本身的硬实力,也离不开它那星光熠熠的顾问团——Jim Keller(苹果、AMD、特斯拉、英特尔的前技术大牛)、Nat Friedman(GitHub前CEO)、Philip Rosedale(Second Life创始人)和Bill Warner(Avid Technology创始人)这些业界大佬都在为它出谋划策。
Midjourney能这么快火起来,可不是撞大运。它那独特的出图风格、相对亲民的使用门槛(一开始主要靠Discord),还有围绕它形成的那个热闹非凡的社区,都是吸引用户的法宝。大家不光能自己动手做图,还能在社区里分享、学习,碰撞出新的灵感火花。这种自给自足的模式,加上顶级顾问的保驾护航,也似乎在告诉我们,Midjourney想走的不是那种快速扩张然后“卖身”的短线玩法,而是踏踏实实搞技术创新,奔着更长远的目标去的。
1.3 核心技术揭秘:图像背后的“魔法”
想跟Midjourney互动,主要还是通过它在Discord平台上的机器人(Bot)。你只要输入以/imagine开头的指令和文字提示,它就开始干活了。这背后的“魔法”,主要靠的是先进的机器学习算法,特别是大名鼎鼎的扩散模型(Diffusion Models)。
扩散模型到底是怎么回事? 通俗点说,你可以把扩散模型的工作原理想象成一个“从乱七八糟到井井有条”的逆向工程。首先,模型学习怎么把一张清晰的图片一点点加上噪点,直到它完全变成一堆随机噪声(这是前向过程)。然后呢,模型再学习这个过程的“倒放”:从一堆随机噪声开始,一步步把噪点去掉,最终根据你给的文字提示,重新造出一张清晰、具体的图像(这是反向过程)。就是这么个逐步去噪、精炼的过程,让模型能生成那些细节满满、又符合你要求的全新图像。
除了扩散模型,Midjourney还用上了自然语言处理(NLP)技术,这样它才能看懂你输入的文字提示,把它们翻译成机器能理解的指令,好指导图像生成。
Midjourney有个特别亮眼的地方,就是它默认生成的图片往往都特别有美感和艺术范儿,更像是画出来的效果。它在色彩搭配、光影处理、细节清晰度还有构图平衡(比如对称性、透视感)这些方面都表现得相当出色。正是这种对“美”的执着,让它在一众AI绘画工具里显得那么与众不同。
说到底,Midjourney的成功,不光是因为用了什么牛X的基础算法(比如扩散模型),更关键的是它对模型的精心调校、训练数据的精挑细选,以及对艺术美学那种深入骨髓的偏爱。这些共同构成了它独特的“艺术滤镜”或者说“秘密武器”,让它生成的图片天生就带着一股子吸引人的艺术气息。虽然一开始完全依赖Discord当主要界面,给一些不熟悉这个平台的朋友造成了点小门槛,但也正因为这样,它迅速孵化出了一个庞大而且互动超频繁的用户社区。这个社区不光是灵感碰撞的火花池,也为Midjourney早期的成长和功能迭代提供了非常宝贵的反馈。
第二部分:玩转Midjourney:功能、版本与提示词的艺术
2.1 驾驭Midjourney:从Discord到网页的融合之路
一开始,Midjourney主要是在Discord平台上为大家服务的。你需要加入它的官方Discord服务器,在指定的频道(比如“newbies”新手村)或者跟Midjourney Bot私聊,用指令来创作图像。这种方式对Discord老司机来说可能挺方便,但也确实把一些新朋友挡在了门外。
好在,近些年Midjourney开始给力发展它的官方网站(midjourney.com)了,一步步把它打造成一个功能更全面的独立平台。现在的网页版,不光能让你欣赏自己作品的画廊,还能直接在“Imagine bar”里敲提示词生成图片。你还可以在网页上调整各种设置,用文件夹管理自己的大作,甚至通过新增的聊天页面(Chat page)跟其他订阅用户一起协作交流。
这个从依赖Discord到打造独立Web平台的战略转变,意义可不小。它不光降低了新用户的上手难度,让那些不熟悉Discord的朋友也能轻松玩起来,更重要的是,它给了Midjourney一个自己说了算、功能更丰富的专属地盘。在这个地盘上,Midjourney可以更灵活地推出新功能、优化用户体验,甚至可能集成更复杂的创作工具,再也不用受限于Discord平台的条条框框了。这明摆着,Midjourney正朝着一个更独立、更专业的创作工具方向大步迈进呢。
2.2 核心功能与常用指令:你的创作魔法棒
Midjourney准备了超多功能和指令,帮你精准控制图像的生成过程:
- **
/imagine**:这可是核心中的核心指令,输入它,再加上你的文本提示词,就能召唤出最初的四张图像网格。 - **图像放大 (Upscaling - U1, U2, U3, U4)**:生成的四张图里,你可以挑一张进行放大,得到分辨率更高、细节更丰富的版本。
- **图像变体 (Variations - V1, V2, V3, V4)**:看中了某张图?可以用这个功能生成一组风格相似但细节略有不同的变体,方便你探索不同的创意方向。
- **
/blend**:这个好玩!你可以上传2到5张图片,让Midjourney把它们融合成一张全新的、兼具各个输入图像元素的创意图片。 - **
/describe**:上传一张图,Midjourney会分析它,然后给你生成四条描述性的文字提示词,这些提示词说不定就是你下次创作的灵感来源呢! - **参数 (Parameters)**:在提示词后面加上这些“小尾巴”,可以精细调整图像的生成效果。常用的有:
--ar <宽:高>:设定图像的宽高比,比如--ar 16:9就是电影宽屏。--chaos <0-100>:控制图像结果的多样性和抽象程度,数值越大越“放飞自我”。--no <物体>:负面提示词,告诉AI你不希望在图片里看到什么。--q <.25,.5, 1, 2, 4>:控制图像质量和生成时间(注意,V7版本里这个参数的玩法变了)。--seed <数字>:用相同的种子值和提示词,能生成相似的图像,方便复现和微调。--stop <10-100>:在图像生成到某个百分比时提前喊停,可以搞出些模糊或者未完成的艺术效果。--stylize <数字>或--s <数字>:控制Midjourney艺术风格的应用强度,数值越高风格越浓。--tile:生成可以无缝拼接的纹理图案,做背景、材质超好用。--weird <0-3000>或--w <0-3000>:想来点不一样的?用它探索更奇特、非传统的图像风格(V7版本里这个参数跟--exp有联动)。--v <版本号>:指定你想用的Midjourney模型版本。
- **参考图像 (Reference Images)**:
- **图像提示 (Image Prompts)**:在提示词里塞进图片的URL,能影响生成图像的内容、构图和颜色。
- 风格参考 (Style References -
–sref URL,–sw <0-1000>)**:扔给AI一张或几张图片的URL作为风格参考,它就会努力模仿参考图的整体视觉风格、色彩、纹理等等,但不会照搬具体内容。–sw用来控制风格参考的权重。 - 角色参考 (Character References -
–cref URL,–cw <0-100>)**:提供一张包含角色的图片URL,Midjourney会尝试在新的场景里复现这个角色的特征(比如发型、服装、脸)。–cw控制角色参考的权重。不过,这个功能在V7版本里被全能参考(Omni Reference)取代了。
- **模式 (Modes)**:
- Fast Mode:默认模式,出图快,但会消耗你的Fast GPU时间。
- Relax Mode:出图慢悠悠,但不消耗Fast GPU时间(适合标准及以上订阅计划的朋友们无限畅玩)。
- Turbo Mode:出图速度飙到飞起,但GPU时间消耗也是Fast Mode的两倍。
- Stealth Mode:Pro和Mega订阅计划用户的专属福利,生成的图像不会出现在Midjourney的公共画廊里,隐私保护妥妥的。
- 想看更完整的指令列表?Midjourney的官方文档里都有。
2.3 解读Midjourney版本:从V1到V7,还有Niji模型的进化之路
Midjourney的模型版本,就像软件升级一样,每一次更新换代,都会在图像质量、提示词理解、画面连贯性和新功能上带来实打实的提升。你可以在提示词末尾加上 --v <版本号> 参数,或者在设置里直接选,就能切换不同的模型版本。
- **早期拓荒者 (V1-V3)**:这几个版本为Midjourney打下了坚实的基础,一步步提升了图像生成能力和艺术风格。V2在2022年4月跟大家见面,V3紧随其后,同年7月上线。
- **V4 (2022年11月10日Alpha版发布)**:在图像细节、光照和风格多样性方面有了不小的进步。
- V5/V5.1/V5.2系列:图像的真实感、细节表现,还有对自然语言提示的理解能力,都有了质的飞跃。
- **V6 (2023年12月20日发布,2024年2月14日至7月30日期间是默认扛把子)**:处理长提示词更准了,图像的连贯性和知识储备也上去了,图像提示和Remix功能也更给力了。
- **V6.1 (2024年7月30日发布并接任默认模型)**:出图更连贯,细节和纹理更精细,而且生成速度比V6快了大概25%。
- V7 (Alpha测试版已于2025年4月3日发布):这是Midjourney的最新力作,但还不是默认选项。想尝鲜?你得先去官网上给大概200对图片打打分,解锁你的V7全局个性化配置文件才行。V7版在处理文字和图像提示方面,精准度简直让人惊叹,图像质量在纹理丰富度、细节连贯性(尤其是身体、手部和物体上)方面提升巨大。V7还带来了草稿模式(Draft Mode)和全能参考(Omni Reference)这两大新招,并且通过网页应用支持语音输入提示词,懒人福音啊!不过要注意,V7刚出来的时候,有些功能(比如图像放大、修复、平移、缩放这些)可能会暂时“借用”V6.1的对应功能。
- **V7 个性化 (Personalization)**:这个超酷!通过学习你对图片的喜好(就是你打分建立的那个个人档案),V7能生成更符合你个人审美风格的图片。
- **V7 草稿模式 (Draft Mode)**:GPU消耗减半,速度却能快上大约10倍,虽然质量略逊一筹,但用来快速出点子、迭代创意简直不要太爽!
- V7 全能参考 (Omni Reference -
–oref URL,–ow <权重>)**:允许你把参考图里的特定角色、物体、车辆甚至非人类生物“抠”出来,融入到你的新创作里。不过,这功能会消耗双倍GPU时间,而且目前跟Fast Mode、Draft Mode还有–q 4参数不太兼容。
- Niji模型系列 (比如 Niji 6):这是Midjourney和Spellbrush联手打造的特别版模型,专攻东方美学、动漫和插画风格。Niji模型有自己的网站和Discord服务器哦。Niji 6 (2024年6月7日发布) 在渲染日文(尤其是假名)和简单的汉字方面表现更好,图像细节也有提升,特别是在动漫人物眼睛的结构这些地方,还修复了一些之前版本里的小瑕疵。
下面这个表,帮你快速了解Midjourney主要版本的进化亮点:
表1: Midjourney版本演进亮点一览
| 版本 | 大致发布日期 | 主要改进/特性 |
|---|---|---|
| V1-V3 | 2022年早期-中期 | 打基础,逐步提升图像生成能力和艺术风格 |
| V4 | 2022年11月 (Alpha) | 图像细节、光照、风格多样性显著提升 |
| V5系列 | 2023年 (V5) | 真实感、细节表现、自然语言理解能力大幅增强 |
| V6 | 2023年12月20日 | 长提示词准确性、图像连贯性、知识储备提升,图像提示和Remix功能增强 |
| V6.1 | 2024年7月30日 | 现任默认模型;图像更连贯,细节纹理更精确,生成速度比V6快约25% |
| Niji 6 | 2024年6月7日 | 动漫风格专属;改进日文/简单中文渲染,提升动漫细节(如眼睛结构),修复瑕疵 |
| V7 (Alpha) | 2025年4月3日 | 需解锁个性化配置;文本/图像提示精确度、纹理、细节(身体、手部)大幅提升;引入草稿模式、全能参考、语音输入;部分功能初期可能依赖V6.1的实现 |
Midjourney的版本迭代之路,清晰地展示了它在核心能力(比如图像连贯性、提示词的“听话”程度)上持续精进的决心,同时也没忘了推出像Niji系列这样的专精模型和V7全能参考、个性化设置这样的高级功能,来满足咱们日益多样化和精细化的创作需求。正是这种发展策略,让Midjourney稳稳地坐在AI绘画领域的头把交椅上。
2.4 提示词工程的艺术:打造“一句顶万句”的指令
在Midjourney的世界里,提示词(Prompt)就是连接你天马行空的想象和AI强大创造力之间的那座桥。想生成高质量、正中下怀的图像?那提示词工程这门艺术,你可得好好琢磨琢磨。
- 明确具体,细节拉满:提示词越具体、描述越生动越好。把主体是什么、在什么环境里、光线怎么样、色彩基调如何、想要啥情绪氛围、构图怎么安排,甚至模拟的相机设置(比如镜头类型、光圈效果)都描绘清楚,AI才能更懂你的心思。
- 结构化思考,更有条理:一个给力的提示词,通常包含这几个关键部分:
- **主体 (Subject)**:画面的核心,比如人物、动物、物体或某个场景。
- **媒介 (Medium)**:想要的艺术形式,是照片、油画、水彩,还是雕塑、像素艺术?
- **风格 (Style)**:特定的艺术流派或视觉风格,比如印象派、赛博朋克、蒸汽朋克,或者吉卜力动画那种感觉。
- **环境/背景 (Environment/Setting)**:主体待在哪儿。
- **光照 (Lighting)**:是柔和的光,还是戏剧性的光照?是黄金时刻的暖阳,还是霓虹灯下的迷离?
- **色彩 (Color)**:主色调是什么?色彩饱和度高还是低?要单色还是彩色?
- **构图 (Composition)**:是特写,还是远景?是鸟瞰视角,还是别的?
- 锦上添花与参数调控:比如人物的情感表达、特定的纹理质感,再加上Midjourney的那些控制参数。
- 简洁也很重要:虽然细节要够,但也别太啰嗦。Midjourney可能hold不住太长的指令,一般超过40-60个词之后,后面的内容权重会降低,甚至可能被直接忽略掉。
- 关键词大法好:熟练运用跟艺术风格(比如“立体主义”、“装饰风艺术”、“浮世绘”)、艺术媒介(比如“钢笔素描”、“丙烯画”、“十字绣”)和摄影术语(比如“电影感光效”、“散景”、“浅景深”)相关的关键词,能让你的图像表现力瞬间提升好几个档次。
- **图像提示来助攻 (Image Prompts)**:除了文字,你还可以扔给AI一个或多个图片的URL作为提示的一部分。这些参考图能影响生成图像的风格、构图、颜色甚至内容。
- 负面提示帮你“避坑” (Negative Prompts -
--no)**:用--no参数,明确告诉AI你不希望在图片里看到哪些元素,这样就能更精准地控制结果。比如,--no text就能尽量避免图片里出现文字。 - 权重分配有讲究:用双冒号
::可以给提示词的不同部分分配不同的权重,或者让AI分别理解这些概念。举个栗子,space ship会被理解成一个整体的“宇宙飞船”,而space:: ship则会引导AI分别考虑“太空”和“船”,结果可能就是一艘在太空中航行的普通船只。 - 参数熟能生巧:把前面提到的各种参数(像
--ar,--stylize,--chaos这些)组合运用,灵活微调,是提升作品质量的关键一步。 - 大胆尝试,不断迭代:AI对提示词的理解有时候确实有点“玄学”,所以别怕失败,多试试不同的说法,调整调整参数,观察结果,再改进,这是掌握提示词工程必不可少的过程。
下面这张表,给你总结了一些关键的提示词技巧和例子,不妨参考一下:
表2: 关键提示词技巧与示例
| 技巧 | 描述 | 示例提示词片段 |
|---|---|---|
| 指定艺术风格 | 明确你希望图像呈现哪种艺术流派。 | … in the style of Van Gogh 或 … Art Deco poster |
| 描述媒介与材质 | 指出图像应该模仿什么样的创作媒介或物体材质。 | … oil painting on canvas 或 … made of polished chrome |
| 控制光照与氛围 | 用光照和情绪相关的词汇来设定场景的基调。 | … cinematic lighting, moody atmosphere |
| 使用图像URL作为参考 | 提供图片链接,让它影响最终图像的风格、构图或内容。 | https://example.com/image.jpg a portrait in this style |
负面提示 (--no) |
排除掉那些你不想在图像中看到的元素。 | … a forest scene –no people |
调整宽高比 (--ar) |
定义图像的尺寸比例,比如宽屏还是方形。 | … –ar 16:9 |
控制风格化程度 (--s) |
调整Midjourney默认艺术风格应用的强度。 | … –s 750 (风格化程度较高) 或 … –s 50 (风格化程度较低) |
| 角色/风格参考 | V6用--cref/--sref,V7用--oref``/–sref,V7用–oref`,配合URL实现角色或风格在不同图片间的一致性。 |
… –sref https://ref.jpg –cref https://char.jpg (V6) / –oref (V7) |
2.5 V7与Niji 6 高级特性深度剖析
Midjourney V7和Niji 6的到来,给咱们带来了更强大的创作工具和更精细的控制能力,简直是如虎添翼。
2.5.1 V7 全能参考 (Omni Reference - –oref, –ow) 详解
全能参考(Omni Reference)可以说是V7版本里一项具有革命性的功能。它能让你从一张参考图里“提取”出角色、物体、车辆甚至非人类生物的视觉特征,然后把这些特征应用到全新的创作中去。
怎么用?
- 网页版:在
midjourney.com的Imagine Bar里,点一下那个图像图标打开图像面板,上传或者选择你已经上传好的图片,然后把它拖到“Omni Reference”区域。记住,一次只能用一张图作为全能参考。- Discord版:在你的提示词末尾加上参数
–oref,后面跟上你想参考的图片的有效URL。同样,也只能用一张参考图。
- Discord版:在你的提示词末尾加上参数
- 全能权重 (Omni Weight -
–ow)**:这个参数用来控制参考图对最终生成结果的影响力有多大,范围是1到1000,默认是100。一般建议把权重保持在400以下,这样结果会比较稳定,除非你同时用了非常高的风格化值(--stylize)。权重越高,AI就越倾向于复制参考图的细节;权重越低,AI就更多地听从文字提示,同时从参考图里提取一些比较概括的特征。 - 最佳实践小贴士:
- 文字提示要清晰:全能参考得跟明确的文字提示词搭配使用才行。文字对于描绘整体场景和那些参考图没能涵盖的额外细节来说,太重要了。
- 想换风格?这么办:如果希望生成图像的风格跟参考图不一样,建议在提示词的开头和结尾都提一下你想要的风格,同时可以考虑结合使用风格参考(
--sref),并且适当降低全能参考的权重(--ow)。权重比较低的时候,你需要在文字里更清楚地描述那些希望保留的物理特征。 - 突出主体是王道:把参考图裁剪一下,让它聚焦在你想要嵌入的核心角色或物体上,背景别太乱,免得干扰AI的识别。
- 多角色也试试看:虽然一次只能用一张图做全能参考,但你可以试试用那种包含多个角色或人物的图片,然后在提示词里分别描述他们。
- 局限性和成本,心里要有数:
- 用全能参考会消耗双倍的GPU时间,钱包要捂紧点。
- 目前跟V6.1的一些编辑功能(比如局部重绘、扩展绘画、平移、缩小)不太兼容。如果想编辑这类图像,得在编辑器里把图像参考和相关参数去掉才行。
- 跟Fast Mode、Draft Mode还有
--q 4参数也不太合拍。 - 用的时候可能会遇到更严格的内容审查,有时候看着没啥问题的提示也可能被拦下来,不过好在被拦截的任务不消耗GPU时间。
- 创意应用场景举例:
- 角色保持一致:在不同的场景、不同的故事里,让同一个角色的外观特征(比如脸、发型、特定服装)保持不变。举个栗子,拿一张“张三”的肖像做参考,就能在各种情境下生成带有他特征的人物图像。
- 物体/道具“植入”:把特定的物体(比如带特定图案的咖啡杯、品牌Logo)精准地“塞”到各种图像里,保证它的颜色、形状和关键细节都对得上,这对产品设计和营销来说简直太有价值了。
- 非人类生物与爱宠:给你的宠物创作一系列风格一致的肖像画,或者把想象中的生物(比如一个龙的模型)的特征融入到不同的作品里。
- 环境细节“神还原”:比如说,用一张城市风光照片做参考,就能在生成的不同视角或氛围的城市图像中,保持关键建筑的细节和风格基本一致。
- 网页版:在
2.5.2 V7 个性化与草稿模式:更懂你,更高效
- **个性化Personalization)**:这绝对是V7的一大亮点!你先花点时间给大概200对图片打打分,系统就会学习你的审美偏好,然后为你生成一个V7全局个性化配置文件。之后,只要你用V7模型(可以通过
--p参数或者网页UI里的开关激活个性化功能),生成的图像就会更贴近你个人的风格和喜好,比如你偏爱的色彩、构图、主题等等。这感觉就像是AI的“艺术眼光”也能为你“量身定制”了。 - 草稿模式 (Draft Mode -
–draft)**:高质量图像生成又费时又费GPU,为了解决这个痛点,V7引入了草稿模式。在这个模式下,图像的渲染速度能提升大约10倍,而GPU成本只有标准模式的一半!虽然生成的图像质量会低一些,细节也少一些,但用来快速构思、测试不同的创意方向、或者搞搞头脑风暴,简直是太合适了。你可以在草稿模式下快速迭代,等有了满意的雏形,再选择把草稿图像“增强”(enhance)或者“重新渲染”(re-render)成全质量版本。草稿模式还支持语音输入提示词,进一步提升了创作效率,简直不要太方便!
2.5.3 Niji 6 的独特魅力
Niji系列模型是Midjourney专为动漫和插画风格打造的“特供版”,Niji 6作为这个系列的最新成员,带来了不少让人眼前一亮的改进。
- 核心定位:就是冲着生成具有东方美学、日系动漫和各种插画风格的图像去的。
- 文字渲染有进步:Niji 6在图像里渲染日文(特别是平假名、片假名)和简单的中文汉字时,表现更靠谱了。你可以在提示词里用引号把少量文字包起来,Niji 6会努力把它们融入画面,不过太复杂或者太长的文本,处理起来还是有点吃力。
- 图像细节更上一:尤其是在动漫角色特有的细节上,比如眼睛的结构、光泽感,还有复杂发型的表现,都更加出色了。
- 多角色处理能力增强:Niji 6在处理包含多个角色的提示词时,比以前更得心应手了,能更好地生成角色之间互动的场景。不过有时候还是可能出现特征混淆或者不太一致的情况,需要你多点耐心,通过迭代来调整。
style raw参数的妙用:如果你觉得Niji 6默认的动漫风格太“冲”或者太“卡通”了,不符合你的口味,可以在提示词里加上style raw,这样能得到一种相对没那么夸张、更接近原始模型输出的风格。- 怎么用Niji 6? 你可以加入Midjourney官方的Niji服务器,在特定的频道里使用;或者在自己的服务器或私聊里,通过在提示词末尾加上
--niji 6参数来调用Niji 6模型。 - 其他调整小技巧:试试不同的
–stylize值(通常1000左右可能会有意想不到的效果),还有比较低的–chaos值(0到6之间),这些都有助于获得更可控、更美观的结果。
V7和Niji 6里的这些高级特性,比如全能参考、个性化、草稿模式,还有Niji对特定艺术风格的精进,都充分体现了Midjourney在努力提升图像生成质量的同时,也在想方设法赋予用户更强的控制力、满足大家的个性化需求,并且不断优化创作流程。这些功能让Midjourney不仅仅是一个图像生成器,更像一个能跟创作者深度协作的智能好伙伴。
下面这张表总结了V7版本部分功能兼容性及关键参数(信息截至撰文时,即2025年5月):
表3: Midjourney V7 特性兼容性与关键参数 (信息截至撰文时,2025年5月)
| 特性/参数 | V6.1 支持情况 | V7 支持情况 (Alpha) | 备注 |
|---|---|---|---|
| 最大宽高比 | 任意 | 任意 | |
| 变体 (Variations) | 强 & 弱 | 强 & 弱 | |
| 放大器 (Upscalers) | Subtle & Creative | 使用V6.1放大器 | V7自身的放大器仍在开发中,敬请期待 |
| 平移 (Pan) | 支持 | 使用V6.1平移功能 | |
| 缩放 (Zoom Out) | 支持 | 使用V6.1缩放功能 | |
| Remix模式 | 支持 | 支持 | |
| 个性化 (Personalization) | 不支持 (V6.1无此概念) | 支持 (通过评分解锁,支持情绪板 Moodboards) | V7核心特性,让AI更懂你的菜 |
| 编辑器 (Editor) | 支持 (V6.1 Inpainting) | 完整编辑器 (部分高级编辑可能初期依赖V6.1) | V7的编辑器功能更全面,值得探索 |
角色参考 (--cref) |
支持 | 由全能参考 (--oref) 取代 |
--cref 及 --cw 在V7中已“退休” |
全能参考 (--oref) |
不支持 | 支持 | V7新大招,用于嵌入参考图像中的元素 |
全能参考权重 (--ow) |
不支持 | 支持 (1-1000) | 控制--oref影响程度,调得好有奇效 |
风格参考 (--sref) |
支持 | 支持 (随机风格代码与V6.1不匹配) | |
风格参考权重 (--sw) |
支持 | 支持 | |
| 图像提示 | 支持 | 支持 | |
图像权重 (--iw) |
支持 | 支持 | |
| 多重提示 | 支持 | 支持 | |
--no 参数 |
支持 | 支持 | 不想要什么,大胆说出来 |
--quality (--q) |
0.25, 0.5, 1, 2 | 1, 2, 4 (工作方式不同) | V7的 --q 参数有调整,具体看官方文档怎么说 |
--repeat (--r) |
支持 | 支持 | |
--seed |
支持 | 支持 | |
--stop |
支持 | 支持 | |
--chaos |
支持 | 支持 | |
Raw Mode (--style raw) |
支持 | 支持 | |
--stylize (--s) |
支持 | 支持 | |
--tile |
支持 | 支持 | |
--weird (--w) |
支持 | 支持 (V7中与 --exp 参数相关) |
|
Niji 版本 (--niji) |
--niji 6 |
--niji 6 |
|
| Relax Mode | 支持 | 支持 | 慢慢来,不着急 |
| Fast Mode | 支持 | 支持 (全能参考不兼容) | |
| Turbo Mode | 支持 | 支持 (全能参考不兼容) | |
Draft Mode (--draft) |
不支持 | 支持 | V7新特性,快速低成本出草稿,迭代神器 |
第三部分:Midjourney API密钥获取终极指南:官方缺席下的“API接口方案”
对于那些想把Midjourney强大的图像生成能力整合到自己开发的应用程序或自动化流程里的朋友们来说,API接口那可是刚需。但是,Midjourney在API这事儿上的策略,跟别人家还真不太一样。
3.1 官方API现状:为何“官方”迟迟不露面?
首先得跟大家明确一个核心事实:截至撰文时(2025年5月),Midjourney官方并没提供任何公开的API (Application Programming Interface) 供开发者使用。这就意味着,你没法像接入其他很多SaaS服务那样,通过官方渠道正儿八经地拿到API密钥,然后进行程序化调用。
3.1.1 Midjourney服务条款里关于自动化的“红线”
Midjourney的官方服务条款(Terms of Service)在这方面说得挺明白。条款里通常会写着,禁止使用自动化工具去访问、交互,或者通过服务来生成“资产”(也就是图片)。此外,服务条款还禁止转售或重新分发Midjourney服务,或者对服务的访问权限进行倒卖。
这些条款直截了当地告诉我们,任何未经授权的自动化行为,包括用非官方API或者脚本,都可能被认为是违反服务条款的,后果嘛,轻则Midjourney账户被暂停,重则可能被永久封禁。
Midjourney目前不提供官方API,并且对自动化操作持非常谨慎的态度,这背后可能有好几层考虑。首先,这有助于把控用户体验,确保图像生成过程符合他们的设计理念和社区准则。其次,大规模的API调用可能会给服务器稳定性带来巨大压力,并且显著增加GPU计算成本,这对于一个自力更生的团队来说,是必须严格控制的。再者,不受控制的API访问,也可能增加图像被滥用于制造虚假信息或侵权内容的风险。然而,这种官方的“缺席”,跟开发者社区对程序化访问的强烈渴望之间,形成了一种微妙的张力,也直接催生了非官方API解决方案市场的悄然兴起。
3.2 非官方API解决方案大盘点
正因为官方API的“不见踪影”,以及开发者们对于自动化生成图像、把Midjourney整合到工作流或产品里的那种迫切需求,市面上就冒出来不少由第三方开发的非官方API服务。这些服务通常是通过模拟用户在Discord里的操作,或者利用其他一些技术手段,来间接实现对Midjourney功能的调用。
3.2.1 主流第三方API服务商简介
下面这几家,是在社区里被提及比较多,或者提供了相对完整文档的非官方API服务商:
- **MJAPI.io (Fairy & Self Served)**:这家服务商提供API密钥,号称支持自动选择并放大图像之类的功能。他们的工作模式可能包括“Fairy”(听起来像是共享账户池)和“Self Served”(可能是让用户自己提供账户)两种。不过,有调研发现他们公开的信息比较少,具体情况可能需要深入了解。
- **Midjourney Client (Dart/Flutter)**:这是一个面向Dart和Flutter开发者的非官方客户端库,也托管在GitHub上。它通过用户的Discord账户令牌(Token)跟Midjourney机器人进行交互。开发者明确说了,这个库的稳定性还没经过充分测试,不建议用在生产环境里。
- GoAPI.ai: 这家同样提供BYOA(Bring Your Own Account,就是自带账户)和(Pay Per Use,按使用付费)两种选项。功能集跟uiuiAPI差不多,支持Midjourney的多种核心操作,还特别强调他们有防止账户被封禁的特性(不过效果怎么样,还得用户自己判断)。
- uiuiAPI.com: 提供便捷接入模式:按实际使用量付费。他们API支持的功能还挺全的,包括Imagine、Upscale、Variation、Describe、Blend、Inpaint、Zoom、Pan,还有风格参考(sref)和角色参考(cref)这些高级参数都支持。
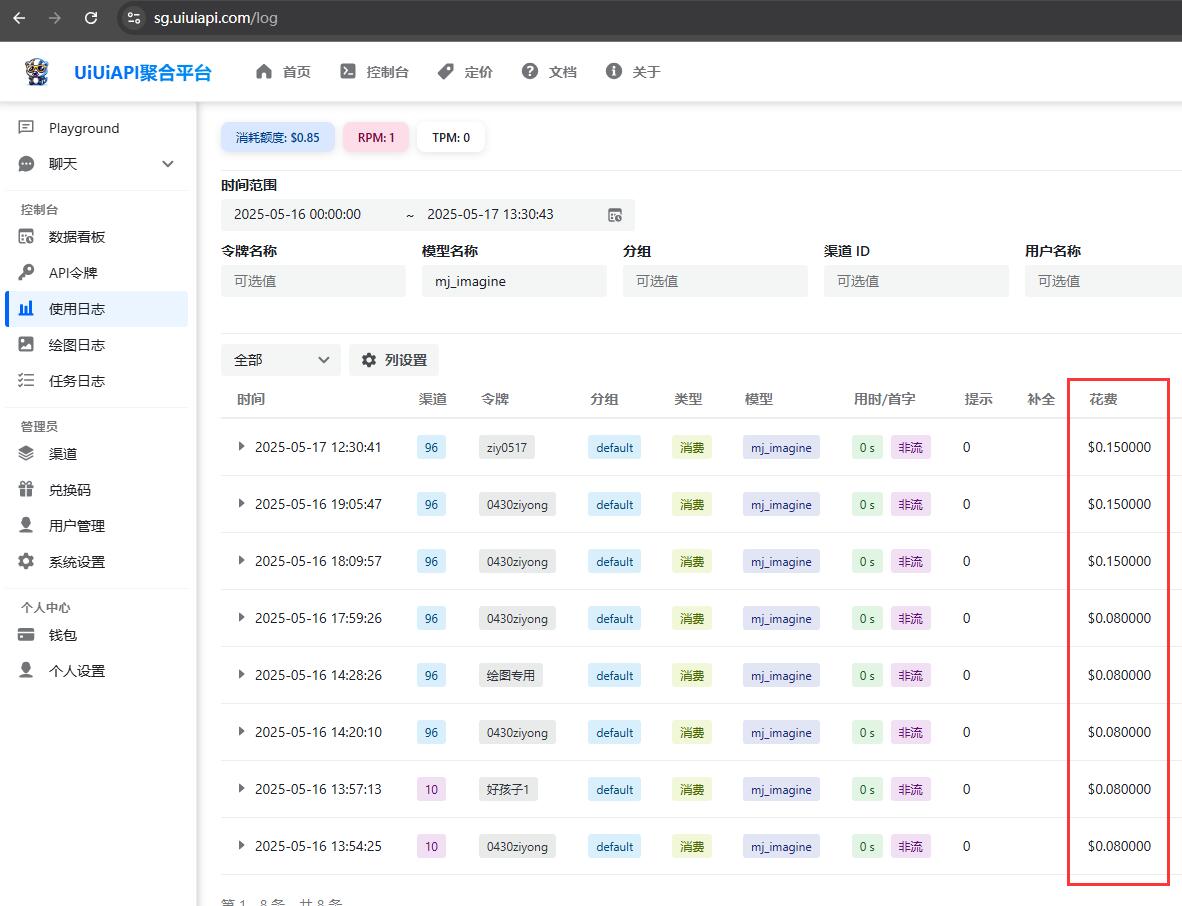
3.2.2 工作模式深究:BYOA (自带账户) vs. uiuiAPI (按使用付费)
这些非官方API服务商,主要采用下面这两种运营模式:
- **BYOA (Bring Your Own Account - 自带账户)**:在这种模式下,你需要把你已经订阅了的Midjourney账户凭证交给API服务商,由他们来托管你的账户,并通过它来执行API调用。API生成图像所消耗的GPU额度(比如Fast Hours)会直接从你自己的Midjourney账户里扣。
- 优点:对于那些已经有Midjourney付费订阅,而且还有没用完的GPU额度的朋友来说,单张图片的生成成本可能会相对低一些。
- 缺点:安全风险比较高,毕竟你把自己的Midjourney账户控制权交给了第三方。一旦服务商操作不当,或者被Midjourney检测到异常活动,你自己的个人账户可能就会面临警告、暂停甚至被封禁的风险。PiAPI.ai和GoAPI都提供这种模式。
- **uiuiAPI (Pay Per Use - 按使用付费)**:这种模式下,你不需要有自己的Midjourney账户(或者不想用自己的账户),而是直接向API服务商按API调用次数付费。服务商会维护一个Midjourney账户池,用这些账户来处理用户的API请求。
- 优点:你不用直接承担自己Midjourney账户被封禁的风险,因为用的是服务商的账户。对于那些没有Midjourney订阅,或者只需要少量调用的用户来说,可能更灵活一些。
- 缺点:通常情况下,单次API调用的成本会比BYOA模式下用自己额度的成本要高,因为服务商需要覆盖他们的账户成本、运营成本和风险成本。uiuiAPI和GoAPI也提供这种模式。举个例子,uiuiAPI和GoAPI的PPU模式下,一次imagine任务的费用根据模式(Relax, Fast, Turbo)的不同,从$0.02到$0.20不等,需要注意:服务商会根据成本调整价格。
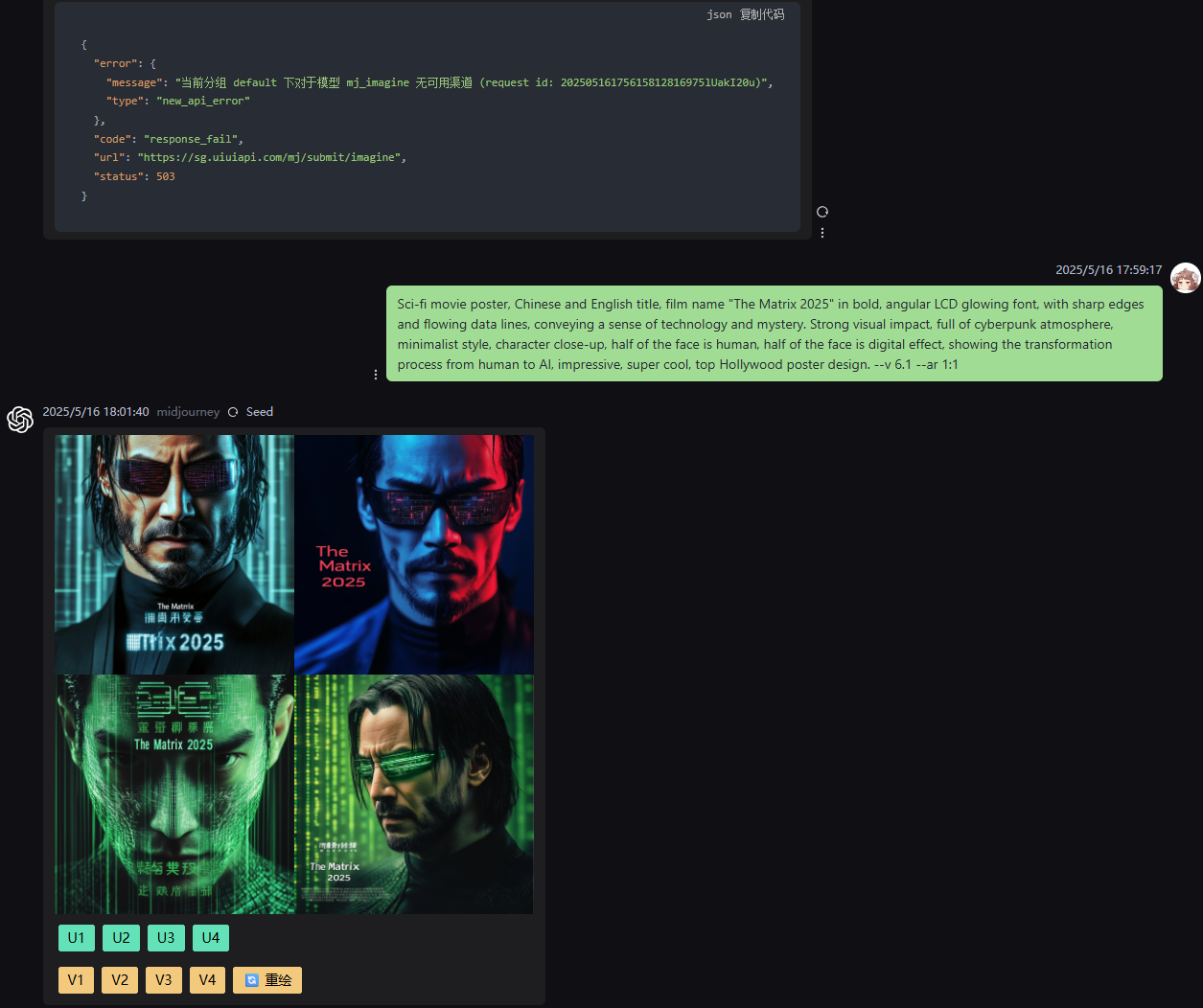
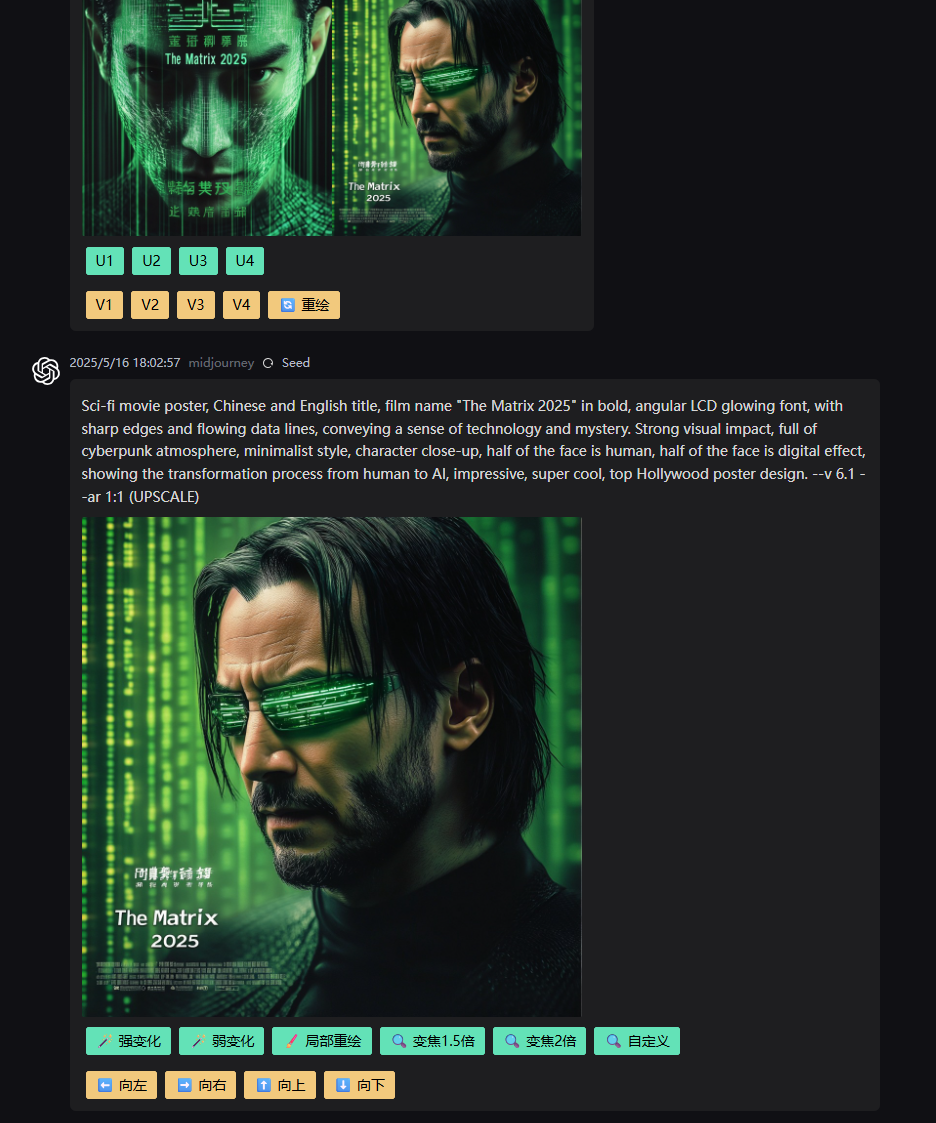
这两种模式,清清楚楚地摆明了用户在使用非官方API时,必须在风险和成本之间做出的权衡。选BYOA模式,你是想用较低的边际成本换取API接入,但同时也把个人账户置于了潜在的风险之下。选PPU模式,你支付了更高的价格,为的是换取对个人Midjourney账户的风险隔离。开发者在做选择的时候,一定要仔细评估自己的需求、预算,还有对风险的承受能力。
3.3 实战教程:如何获取并使用非官方Midjourney API Key
因为没有官方API,所以获取和使用API Key的过程,完全取决于你选了哪家第三方服务商。下面的步骤,我们以一家提供了清晰文档和仪表盘的主流服务商(比如GoAPI.ai或PiAPI.ai)为例,给大家做一个通用的说明。
3.3.1 精挑细选,找到合适的API服务商
选服务商的时候,可得睁大眼睛,综合考虑下面这些因素:
- 功能全不全:你需要的Midjourney指令和参数(比如Imagine, Upscale, Variations,
–sref,–cref,–oref这些)它支不支持? - 价格怎么样:是BYOA还是PPU模式?具体的价格结构清不清晰,透不透明?符不符合你的预算?
- 文档好不好懂:有没有详细、易懂的API文档和集成指南?
- 社区给不给力:有没有活跃的社区(比如Discord服务器)或者客服渠道?遇到问题的时候能不能及时找到人帮忙?
- 口碑稳不稳定:服务商运营了多久?用户评价怎么样?服务稳定性有没有保障(虽然非官方服务很难保证绝对稳定)?建议优先考虑那些在这些方面表现更出色的服务商,比如说,PiAPI.ai和GoAPI.ai就提供了相对全面的信息,可以多看看。
3.3.2 uiuiAPI调用代码示例
💡 请求示例
提交Imagine任务 ✅
curl --location --request POST 'https://你的uiuiapi服务器地址/mj/submit/imagine' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"botType": "MID_JOURNEY",
"prompt": "Cat",
"base64Array": [],
"accountFilter": {
"channelId": "",
"instanceId": "",
"modes": [],
"remark": "",
"remix": true,
"remixAutoConsidered": true
},
"notifyHook": "",
"state": ""
}'
响应示例:
{
"code": 1,
"description": "提交成功",
"properties": {},
"result": 1320098173412546
}
提交Blend任务 ✅
curl --location --request POST 'https://你的uiuiapi服务器地址/mj/submit/blend' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"botType": "MID_JOURNEY",
"base64Array": [
"data:image/png;base64,xxx1",
"data:image/png;base64,xxx2"
],
"dimensions": "SQUARE",
"accountFilter": {
"channelId": "",
"instanceId": "",
"modes": [],
"remark": "",
"remix": true,
"remixAutoConsidered": true
},
"notifyHook": "",
"state": ""
}'
响应示例:
{
"code": 1,
"description": "提交成功",
"properties": {},
"result": 1320098173412546
}
提交Describe任务 ✅
curl --location --request POST 'https://你的uiuiapi服务器地址/mj/submit/describe' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"botType": "MID_JOURNEY",
"base64": "data:image/png;base64,xxx",
"accountFilter": {
"channelId": "",
"instanceId": "",
"modes": [],
"remark": "",
"remix": true,
"remixAutoConsidered": true
},
"notifyHook": "",
"state": ""
}'
响应示例:
{
"code": 1,
"description": "提交成功",
"properties": {},
"result": 1320098173412546
}
提交Modal ✅
curl --location --request POST 'https://你的uiuiapi服务器地址/mj/submit/modal' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"maskBase64": "",
"prompt": "",
"taskId": "14001934816969359"
}'
响应示例:
{
"code": 1,
"description": "提交成功",
"properties": {},
"result": 1320098173412546
}
提交swap_face任务 ✅
curl --location --request POST 'https://你的uiuiapi服务器地址/mj/insight-face/swap' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"sourceBase64": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBwgHBgkIBwgKCgkLDRYPDQwMDRsUFRAWIB0iIiAdHx8kKDQsJCYxJx8fLT0tMTU3Ojo6Iys/RDnYdriP1wsS81kwU8OVs/R3xu8s6bX7+zYnOH8coSqpmRSBjqerjcBlr2OB/lbAf/2Q==",
"targetBase64": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBwgHBgkIBwgKCgkLDRYPDQwMDRsUFRAWIB0iIiAdHx8kKDQsJCYxJx8fLT0tMTU3Ojo6Iys/RD849k="
}'
响应示例:
{
"code": 0,
"description": "string",
"result": "string"
}
执行Action动作 ✅
curl --location --request POST 'https://你的uiuiapi服务器地址/mj/submit/action' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"chooseSameChannel": true,
"customId": "MJ::JOB::upsample::1::82c51c9d-bc33-4c07-a471-36c3dcb1a6f0",
"taskId": "1728781324658687",
"accountFilter": {
"channelId": "",
"instanceId": "",
"modes": [],
"remark": "",
"remix": true,
"remixAutoConsidered": true
},
"notifyHook": "",
"state": ""
}'
响应示例:
{
"code": 1,
"description": "提交成功",
"properties": {},
"result": 1320098173412546
}
上传文件到discord ✅
curl --location --request POST 'https://你的uiuiapi服务器地址/mj/submit/upload-discord-images' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data-raw '{
"base64Array": [],
"filter": {
"channelId": "",
"instanceId": "",
"remark": ""
}
}'
响应示例:
{
"code": 0,
"description": "string",
"result": [
"string"
]
}
根据ID列表查询任务 ✅
curl --location --request POST 'https://你的uiuiapi服务器地址/mj/task/list-by-condition' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Content-Type: application/json' \
--data-raw '{
"ids": []
}'
响应示例:
[
{
"action": "IMAGINE",
"buttons": [
{
"customId": "string",
"emoji": "string",
"label": "string",
"style": 0,
"type": 0
}
],
"description": "string",
"failReason": "string",
"finishTime": 0,
"id": "string",
"imageUrl": "string",
"progress": "string",
"prompt": "string",
"promptEn": "string",
"properties": {},
"startTime": 0,
"state": "string",
"status": "NOT_START",
"submitTime": 0
}
]
指定ID获取任务 ✅
curl --location --request GET 'https://你的uiuiapi服务器地址/mj/task/{id}/fetch' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Content-Type: application/json'
响应示例:
{
"action": "IMAGINE",
"buttons": [
{
"customId": "string",
"emoji": "string",
"label": "string",
"style": 0,
"type": 0
}
],
"description": "string",
"failReason": "string",
"finishTime": 0,
"id": "string",
"imageUrl": "string",
"progress": "string",
"prompt": "string",
"promptEn": "string",
"properties": {},
"startTime": 0,
"state": "string",
"status": "NOT_START",
"submitTime": 0
}
获取任务图片的seed ✅
curl --location --request GET 'https://你的uiuiapi服务器地址/mj/task/{id}/image-seed' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer $UIUIAPI_API_KEY' \
--header 'Content-Type: application/json'
响应示例:
{
"code": 0,
"description": "string",
"result": "string"
}
第四部分:Midjourney的应用场景与未来畅想
Midjourney凭借它那强大的图像生成能力和独树一帜的艺术风格,已经在很多领域里展现出了广泛的应用潜力,并且还在持续塑造着咱们视觉内容的未来。
4.1 应用领域遍地开花:从艺术设计到商业营销
- 艺术创作与概念设计:对于艺术家、插画师和设计师们来说,Midjourney简直就是一个强大的灵感加油站和创作好帮手。它能飞快地生成概念艺术草图,帮你探索新的视觉风格,创作数字艺术品,甚至还能辅助传统绘画的构思过程。艺术家们用它来打破传统手法的条条框框,尝试那些以前想都不敢想的视觉组合。
- 游戏开发新助力:在游戏开发流程里,Midjourney也被派上了大用场,比如快速创建角色概念图、设定环境氛围、设计道具,甚至是制作游戏里的纹理材质。举个例子,独立游戏《Gammadark RPG》就用了Midjourney来生成它大部分的美术素材,这对于那些预算比较紧张的开发者来说,无疑是个非常可行的选择。它能大大加速早期概念验证和原型制作的阶段。
- 市场营销与广告创意:营销人员和广告创意人发现,Midjourney是制作那种能抓住眼球的视觉内容的利器。它可以用来生成独特的广告图像、社交媒体帖子的配图、博客和网站的视觉元素、产品概念展示图等等。通过Midjourney,品牌可以快速测试不同的视觉方案,并且用比较低的成本制作出大量又多样化的营销素材。
- 教育与研究的好伙伴:教育工作者可以利用Midjourney创建生动形象的教学辅助材料,帮助学生理解那些抽象的概念,或者重现历史场景。研究人员也可以用它来把复杂的数据、理论模型或者科学现象变得可视化,让学术报告和出版物更有表现力。
- 其他脑洞大开的创新应用:Midjourney的应用还延伸到了时尚和纺织品设计(比如生成图案、服装概念图)、室内设计(可视化空间布局和装饰风格)、图标和用户界面(UI)设计、漫画与图画小说创作(辅助设计分镜和角色造型),甚至是个人娱乐和兴趣探索等好多方面。
Midjourney的出现,最显著的一点就是大大降低了高质量视觉内容创作的门槛。它让那些可能不具备专业艺术技能,或者缺乏昂贵设计资源的个人、小型团队甚至企业,也能够创造出具有专业水准的图像。这种“视觉创作的民主化”,可以说是Midjourney带来的最深远的影响之一了。营销人员可以快速生成各种各样的广告素材,独立游戏开发者在没有庞大美术团队的情况下也能构建出完整的游戏世界观,这些在以前简直是难以想象的。
4.2 Midjourney的“闪光点”与“美中不足”
虽然Midjourney功能强大到让人惊叹,但它也并非完美无瑕。了解它的优势和局限,能帮助我们更有效地驾驭这个工具。
**优势 (Strengths)**:
出图质量高,艺术感爆棚:Midjourney以其生成图像独特的审美风格和丰富的细节著称,往往能创造出让人眼前一亮的视觉效果。
上手相对容易:跟一些需要配置复杂参数的AI绘画工具比起来,Midjourney通过Discord和逐步完善的网页界面,为非技术用户提供了比较友好的使用体验。
风格控制和定制强:通过精巧的提示词、各种参数,还有参考图像(比如风格参考、全能参考),用户可以对生成图像的风格、内容和构图进行较高程度的控制和定制。
快速迭代,创意无限:Midjourney能在短时间内生成好多张图像变体,极大地加快了创意构思和方案迭代的过程,鼓励用户大胆尝试各种不同的想法。
社区活跃,灵感不愁:庞大而且活跃的Discord社区是Midjourney的一大特色。用户可以在里面交流技巧、分享作品、获取灵感,还能得到官方和社区志愿者的帮助。
**局限与挑战 (Limitations and Challenges)**:理解复杂或叙事性提示词,有时会“掉链子”:尽管V7版本在这方面有所改进,但Midjourney有时候还是可能难以准确抓住复杂提示词里那些微妙的语境、逻辑关系,或者会忽略掉一些关键细节,导致生成的结果跟预期不太一样。
图像里的文字生成,还不够完美:虽然V6和之后的版本加强了在图像中生成可读文本的能力(通过在提示词里用双引号把文字包起来),但文字的准确性和排版美观度还有很大的提升空间,特别是遇到复杂或者比较长的文本时,就更吃力了。
手部、解构等复杂元素的渲染,仍是“老大难”:这是AI绘画普遍面临的难题。尽管Midjourney的V7版本在手部、面部以及其他身体部位的解剖学准确性和自然度方面取得了显著进步,但偶尔还是可能出现一些不太合逻辑或者看起来怪怪的渲染。
对Discord的依赖(虽然在逐步改善):虽然网页版功能越来越完善,但Discord仍然是Midjourney生态系统里非常重要的一部分,这对于那些不熟悉或者不太喜欢用Discord的用户来说,可能会构成一定的障碍。
付费墙拦住了“党”:Midjourney目前没有提供永久免费的使用层级,所有用户都得付费订阅才能持续不断地生成图像。
图像默认“裸奔”:在标准计划下,你生成的图像默认会在Midjourney的公共画廊里展示出来,除非你订阅Pro或Mega计划,并且启用Stealth Mode(隐身模式)。
伦理与法律问题,不容忽视:跟所有强大的AIGC工具一样,Midjourney也面临着版权归属、深度伪造(Deepfakes)、算法偏见、内容滥用(比如生成有害信息或侵犯个人隐私)等等一系列复杂的伦理和法律挑战。Midjourney官方也在不断更新他们的社区准则和内容过滤机制,来应对这些问题。
一个特别值得注意的现象是,尽管Midjourney的输出质量在很大程度上依然遵循“你喂什么,它出什么”的原则(也就是说,提示词的质量直接影响结果),但它内在的那种“艺术滤镜”往往能把即便是相对简单的提示词也“美化”到具有一定视觉吸引力的水平。这是Midjourney的一大核心竞争力,因为它让新手也能轻松获得看起来不错的图像。然而,这也可能掩盖了一个事实:当需要精确控制特定细节时,你还是得依赖高级的提示词技巧。换句话说,你可能很容易得到一张“好看”的图,但要得到一张完全符合你特定意图的“好看”的图,就需要更深入的理解和大量的实践了。
4.3 未来展望:视频、3D,甚至硬件都要玩起来?
Midjourney可没打算只停留在静态图像生成这个领域,它对未来的规划,展现出了向多模态、更深度创作工具演进的勃勃雄心。
- AI视频生成,正在:Midjourney正在积极探索AI视频生成这个新大陆。据它家创始人David Holz透露以及社区里流传的消息,团队内部已经有视频模型在测试了,并且计划通过合作或者自主研发的方式,推出视频生成功能。他们的目标是提供远超当前市场上那些AI视频产品质量的体验,甚至放话说要“比现有产品好10倍”。有消息称,V7版本的视频工具可能会允许用户基于少量图像(比如6张),在几个小时内(比如3小时)生成长达60秒的高质量视频片段。这无疑将给动态内容的创作带来翻天覆地的变化。
- 3D内容生成,未来可期:除了视频,3D内容的生成也是Midjourney的重点发展方向。他们计划扩展3D功能,探索类似“神经辐射场(NeRF-like)”这样的3D建模技术,来实现实时、动态地生成3D对象和环境,这对虚拟设计、游戏开发和元宇宙应用来说,意义重大。一个特别值得期待的里程碑是计划在2025年第二季度推出的“OmniConsistent Character System”(全能一致性角色系统)。这个系统不仅旨在保持角色在2D图像中的一致性,还可能支持生成简单的3D模型,并应用于基础动画。
- 硬件探索,或有惊喜:Midjourney的创始人David Holz在创立Leap Motion的时候,就积累了丰富的硬件开发经验。最近,Midjourney任命了曾在苹果Vision Pro和马斯克的Neuralink项目担任硬件工程管理职务的Ahmad Abbas来领导他们的硬件团队。这一连串的动作强烈暗示,Midjourney可能正在研发自家的硬件产品,大家推测的方向可能包括AR/VR头显设备,或者与AI生成紧密集成的可穿戴设备。这或许是为了给用户提供一个更沉浸、更直观的AI创作与交互体验。
- 平台持续进化,功能不断迭代:Midjourney承诺,在V7版本(Alpha测试已于2025年4月开始)发布后,会以比较快的频率(比如每1-2周)持续推出新功能和改进。大家可得密切关注他们的官方博客、Discord服务器,还有可能的社交媒体渠道(比如X平台账号@midjourney),以便获取最新的官方公告和更新信息。
Midjourney在视频、3D乃至硬件领域的布局,清晰地表明了它的长远目标是构建一个全面的、多模态的生成式AI生态系统。它不再满足于仅仅做一款顶级的2D图像生成器,而是希望成为一个能让用户无缝创作和集成各种AI生成内容的综合性平台。这种战略雄心,预示着Midjourney将在未来的AIGC浪潮中扮演更加核心的角色。
第五部分:uiuiAPi结论:驾驭Midjourney,共创AI艺术新纪元
Midjourney凭借其卓越的图像生成质量、独特的艺术风格和不断进化的功能集,已经深刻地改变了我们对AI辅助创作的认知和实践方式。它不仅为专业艺术家和设计师提供了前所未有的创作利器,也为广大爱好者打开了通往视觉表达的奇妙大门,真正意义上推动了创意生产力的“平民化”。
要想充分挖掘Midjourney的潜力,吃透提示词工程的精髓,理解不同模型版本(尤其是V7和Niji系列)的特性与参数的巧妙运用,是至关重要的。通过精准的语言描述、巧妙的参数组合以及对参考图像的有效利用,你可以将脑海中的奇思妙想,以前所未有的逼真度和艺术性呈现在眼前。
对于开发者朋友们来说,虽然Midjourney目前还没有提供官方API,但第三方非官方API解决方案的出现,在一定程度上满足了程序化接入的需求。然而,在选择和使用这些非官方API时,大家必须清醒地认识到其中存在的服务条款冲突、账户安全、服务稳定性以及数据隐私等潜在风险,并务必采取审慎的态度和必要的防范措施。BYOA和PPU模式各有优劣,你需要根据自身情况仔细权衡利弊。
展望未来,Midjourney在视频生成、3D内容创作乃至硬件领域的探索,预示着一个更加广阔和激动人心的前景。随着技术的不断进步和应用场景的持续拓展,Midjourney有望从一个顶级的图像生成工具,进化为一个多模态的、综合性的AI创作平台。
Midjourney及其同类工具的崛起,并不仅仅是一场技术的革新,更在催化着我们创意角色的演变。传统的创作流程正在被重塑,艺术家和设计师的角色,正逐渐向“AI协作者”、“创意指导者”或“AI提示工程师”转变。我们不再仅仅是内容的直接生产者,更是与AI并肩作战、引导AI实现我们艺术构想的伙伴。这种人机协作的新范式,要求创作者具备新的技能和思维方式,同时也引发了我们对原创性、作者身份和艺术价值的深刻反思。
我们正处在AI艺术新纪元的拂晓时分。真心鼓励每一位对Midjourney感兴趣的朋友,积极去探索它的无限可能,负责任地使用这一强大工具,共同参与塑造AI辅助创作的美好未来。通过不断的学习、实践和创新,我们一定能驾驭Midjourney的力量,将人类的想象力推向新的高峰!




{kind=link}
{kind=link}
{kind=link}
暂无评论,3525人围观